🧠 Method
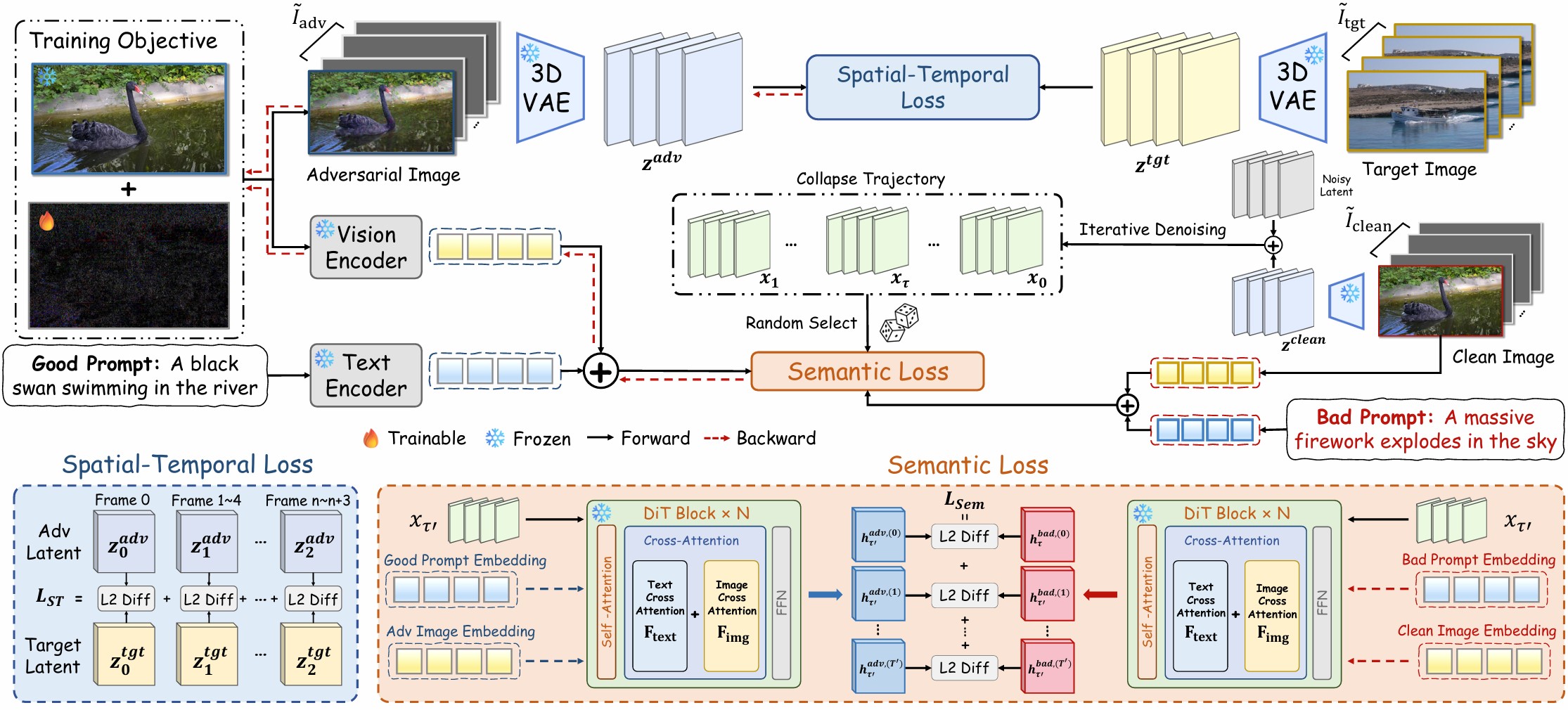
Immune2V Framework. Our method simultaneously targets the spatial-temporal and semantic streams to ensure persistent disruption. The Spatial-Temporal Attack employs a balanced encoder loss and dense targets to recover vanishing optimization signals across temporal segments. The Semantic Attack hijacks DiT guidance by forcing intermediate representations to mimic a precomputed collapse trajectory, neutralizing the model's iterative semantic correction. Together, these joint perturbations induce severe structural breakdown across the entire generated video.